Presentation for the Alliance of Digital Humanities Organizations Annual Conference (9-12 July 2019, Utrecht, Netherlands)
Long Abstract
In humanistic research, Named Entity Recognition is highly useful, but it mines surface data, rather than revealing the complex nature of relationships between these entities. Named Entity Recognition (NER) extracts the names of people, locations, organizations, and, depending on the model, may also extract references to money, percentages, dates, and times, in addition to a miscellaneous class. Although this is certainly useful, NER does not represent the richness of the documents with which we work. For example, consider this fragment from a nineteenth-century French chronicle of Ottoman Algerian history: “To further attach himself [to his ally], Pasha Hassan married his [ally’s] daughter, then he launched troops against the rebel…”[1] In just this short passage, which is not even a full sentence, we find several people referenced who are unnamed. If we look back at the text, we see that Pasha Hassan’s ally is Ben-El-Kadi of Kuku, Algeria, and the rebel is Abd-El-Aziz, but Ben-El-Kadi’s daughter is never named. This occurs frequently in historical source material. Those who remain unnamed are most often women, servants, slaves, and Indigenous people – the very people about whom scholars are most anxious to know more. This short paper presents a work-in-progress: a digital workflow and Python script to mine and model the relationships between extracted entities from French-language documents in order to grapple with the complexity of human relationships and cultures, as well as the perspectives of authors and their informants.
This short presentation will share the complete information extraction code, its accuracy, the resulting visualizations, and a brief analysis from the case study. The method presented has applications far beyond French language and the history of the Middle East and North Africa. For instance, with some adjustments for language, this method would be highly useful in the analysis of The Twenty-Four Histories of China, the official history of the Chinese dynasties between 3000 B.C.E. and the seventeenth century. More broadly, this approach will be of use to scholars interested in identifying and studying relational data, social positions, and networks of both known and previously unknown actors, particularly those who remain unnamed in the source material.
As a test corpus, this project uses four digitized, OCRed, and hand-cleaned nineteenth-century French chronicles of Ottoman Algerian history. The volumes range between 41,341 words and 170,737 words and cover the period 1567 to 1837 with a focus on Constantine, the easternmost province in Algeria. The challenge is to extract not only named entities and their relations to one another, but to extract unnamed persons and their relationships as well. In simple NER, the names Moustafa and Namoun, would be the only extracted data in the following sentence: “Moustafa avait épousé une des filles de Namoun,” but the daughter of Namoun who married Moustafa would not appear.[2] The goal of this project is to uncover the positions and roles of women in Algerian society, so it is essential to locate and retrieve data about unnamed people.
The built-in language models and extensibility of the spaCy natural language processing (NLP) library for Python makes it most suitable for this project.[3] Specifically, spaCy enables researchers to define entities and build custom information extraction systems. Additionally, spaCy’s library features a French language model that has a built-in tagger, parser, and NER, unlike the Natural Language Toolkit or Stanford’s CoreNLP Open Information Extraction system.
To build an information extraction system with spaCy that pulls the desired relational data, we must first identify an extractable pattern by parsing and tracing the dependencies of a sample sentence, as follows:
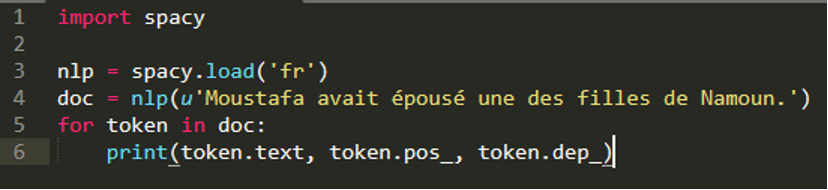
The code above results in the following output in the form: token, part-of-speech, dependency.
- Moustafa PROPN nsubj
- avait AUX aux
- épousé VERB ROOT
- une DET det
- des ADP case
- filles NOUN obj
- de ADP case
- Namoun PROPN nmod
- . PUNCT punct
SpaCy’s visualizer also allows us to view the dependency parse tree using the following code and sample sentence.
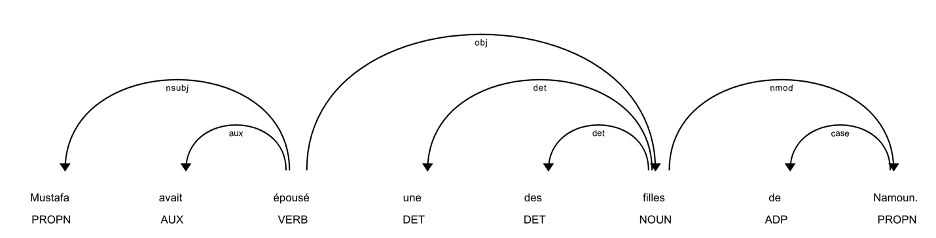
An examination of the parse tree above yields a pattern of parts-of-speech around the keyword “épousé” that we can use to extract the desired information about this relationship. Since we are interested in identifying the relationships between both named and unnamed people, we will look for specific patterns in parts of speech and syntax, as well as the location of proper nouns in relation to keywords. Based on an examination using the concordance method with the sample texts, the following keywords generated the best data: fils, fille, mariage, épous*, gendre, and beau pére (son, daughter, marriage, spouse/to marry, son-in-law, father-in-law). For example, the word “fils,” or “son,” yielded more consistent results for father-son pairs than the word “pére,” or “father.”
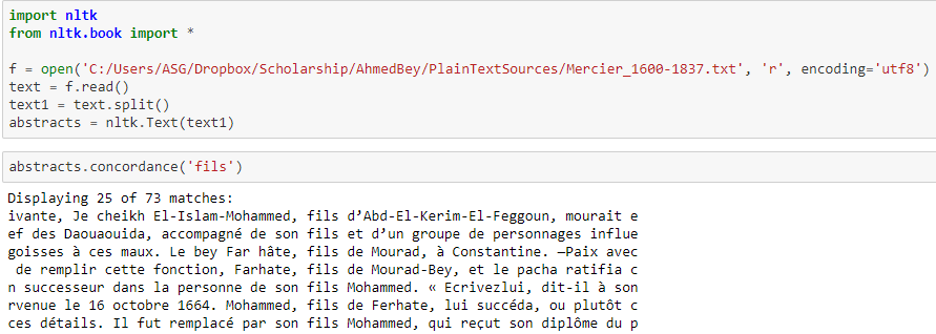
From an examination of the word “fils” in context, as shown above, general patterns emerged, which I then described in a plain text file for each keyword. The patterns for “fils” and the proper output format for each pattern are shown below. These outlines then inform the Python script that uses spaCy’s library to extract the relational data. This script will be made freely available on GitHub following the DH 2019 Conference.

Based on the examples and patterns above, the information extraction system derives relational data that easily translates into node and edge lists.
Network analysis of the extracted data, then, highlights how women, marriage, and kinship connections legitimated Ottoman rule in this case study. Initial findings suggest that women were essential intercultural mediators and conduits to power. Before the French invasion, Algerian women and their mixed ethnicity daughters were key links in the chain that bound Algeria to the Ottoman Empire.
[1] Ernest Mercier, Histoire de Constantine (Constantine, Algeria : J. Marle et F. Biron, 1903), 200. http://gallica.bnf.fr/ark:/12148/bpt6k5735219v.
[2] “Moustafa married one of Namoun’s daughters.” Eugene Vaysettes, Histoire des derniers beys de Constantine : depuis 1793 jusqu’à la chute de Hadj-Ahmed (Constantine : Grand-Alger-Livres, reprinted 2005), 52. (Author’s translation.)
[3] Matthew Honnibal and Ines Montani, spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing (2017). Available at: https://spacy.io/usage/ (Accessed 27 November 2018).